A Practical Approach to Supervised Learning(Classification).
ABOUT:
#Becoming a world-class data scientist. I am an intelligent, highly motivated, purpose-driven and result oriented data scientist passionate about learning new technologies and solving problems in society through data-driven workable and effective solutions.I possess a tough mentality and natural leadership skills. I am enthusiastic about new challenges and learning new technologies in the field of data science and machine learning to increase knowledge and efficiency. I am also advocating for developers with interest in data science
Introduction
Classification in Machine learning is no different from what we know it to be in the English language except that we let the machine do the learning and await its feedback. I am pretty sure you are thinking of it more logically right now.
In classification, machines try to predict a class or a category in which an observation or perhaps observations (data points) belongs. It predicts this class based on a no of features specific to the observation, but general to the category.
Application of Classification in Machine Learning.
 https://www.graphic.com.gh/features/features/strategies-for-dealing-with-e-mail-spam.html]
https://www.graphic.com.gh/features/features/strategies-for-dealing-with-e-mail-spam.html]
Imagine getting an irrelevant or unsolicited messages sent over the Internet, ever wondered how the internet is able to classify them as spam. Spam detection in email service providers can be identified as an application of classification. Machines learn from input data (In this case, data that relates to spam and ham emails ) that have certain features over time, except a relatively shorter period of time than humans do. This is an example of binary classification. There exist cases where you have to classify observations into 3 or more categories(Multi -class classification).
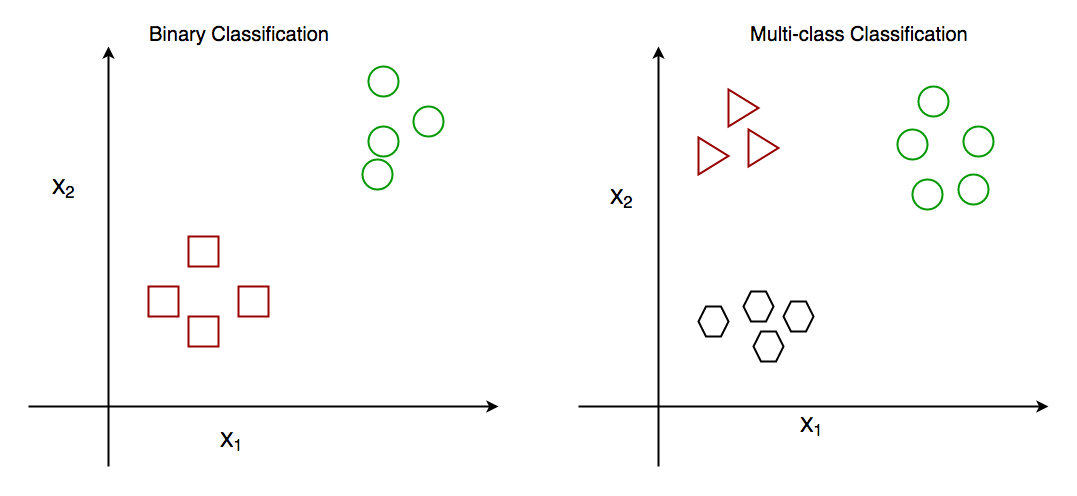 https://medium.com/analytics-vidhya/basic-intuition-on-classification-vs-regression-in-supervised-learning-c50a2fc89de7]
https://medium.com/analytics-vidhya/basic-intuition-on-classification-vs-regression-in-supervised-learning-c50a2fc89de7]
Other applications of classification include credit loan default detection, medical diagnosis ,Image Classification etc.
Classification Algorithms in Machine Learning
The choice of classification algorithm depends greatly on the dataset you are working with. Here are common classification algorithms:
- Logistic Regression
- Support Vector Machines
- K-Nearest Neighbors
- Decision Tree Classifier
- Gradient Boosting Classifier
- Random Forest Classifier
- Naive Bayes Classifiers
Building a Classification model in Sklearn using Breast Cancer Wisconsin (Diagnostic) Data Set as a case study.
Remember what I said about placing an observation in a particular label based on features , let's get practical about that analogy. Building a classification model follows the conventional process of building a machine learning model. Here is the process:
1. Understanding the problem: The first step to solving a problem is actually understanding the problem you intend to solve, because it's in understanding the problem that you know the resources required to solve the problem. In our case study, we aim to predict whether the cancer is benign or malignant.
2. Data collection: The data for this study was gotten from Kaggle. You wanna follow through, here is the data .

3. Setting up the environment: Be sure to have the following packages installed on your computer:
- Python 2.7+ or Python 3
- NumPy
- Pandas
- Scikit-Learn (a.k.a. sklearn)
Relax!!!

[https://www.shutterstock.com/image-photo/stressed-redhead-woman-meditating-relieving-managing-1309082221]
Are you wondering where to download these packages from? I strongly recommend you install Anaconda on your PC. It comes with these packages installed and it also has beautiful integrated development environment(IDE) installed.
4. Import libraries and modules: Import the packages by running the following on your jupyter notebook
NumPy: for Numpy run,
import numpy as np. The np is industry convention so I will advise you stick to it.Pandas: for pandas run,
import pandas as pd.pd is also industry conventionScikit-Learn: Scikit-learn is a free software machine learning library for the Python, it contain loads of packages, I will just import , the packages that you will need.
a. label encoder: run from sklearn.preprocessing import LabelEncoder to import label encoder. Input to machine learning algorithms take in binary data and numerical data, so it is necessary to encode your letters to numbers.
b. train_test_split: After building the model, it is important to evaluate the performance of a machine learning algorithm, train_test_split divides it into two subsets - a train set and a validation set.
To import train_test_split ,run from sklearn.model_selection import train_test_split .
c. Classification Algorithm: For the purpose of this study, we will use a decision tree classifier.
run from sklearn.tree import DecisionTreeClassifier.
You could check out other classifiers on sklearn's documentation page
d. Evaluation metrics: evaluation metrics for classification include ;
- Accuracy, Precision, and Recall
- Log Loss
- F1 score
- AUC
We will use accuracy for this study. Run from sklearn.metrics import accuracy_score to import accuracy.
Note: It's cool to write all the imports in one cell.
 Let's start building
Let's start building
 [https://www.google.com/url?sa=i&url=https%3A%2F%2Fexpertsystem.com%2Fmachine-learning-definition%2F&psig=AOvVaw2UC0JR1F00TnPGsPPnvAw6&ust=1601993041192000&source=images&cd=vfe&ved=0CA0QjhxqFwoTCOCE8bHPnewCFQAAAAAdAAAAABAD]
[https://www.google.com/url?sa=i&url=https%3A%2F%2Fexpertsystem.com%2Fmachine-learning-definition%2F&psig=AOvVaw2UC0JR1F00TnPGsPPnvAw6&ust=1601993041192000&source=images&cd=vfe&ved=0CA0QjhxqFwoTCOCE8bHPnewCFQAAAAAdAAAAABAD]
5. Load data ,preview, and examine the data:
a. load and preview the data:
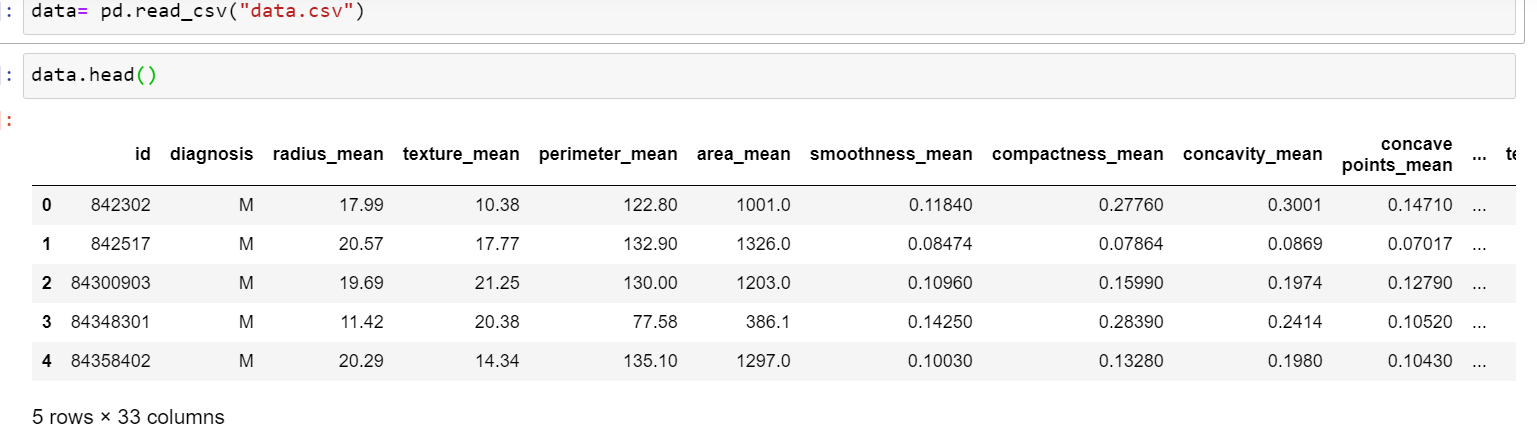
data= pd.read_csv("data.csv") #load data
data.head() # outputs the first rows/observations
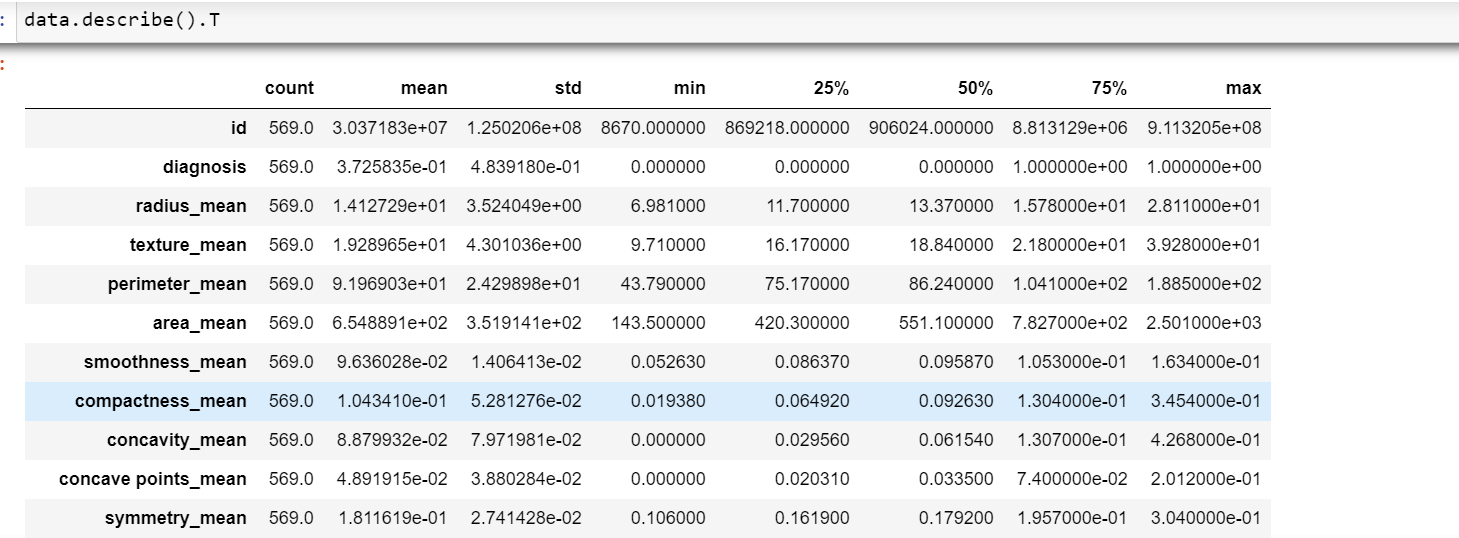
b. Basic statistical description of the data:Run,
data.describe().T
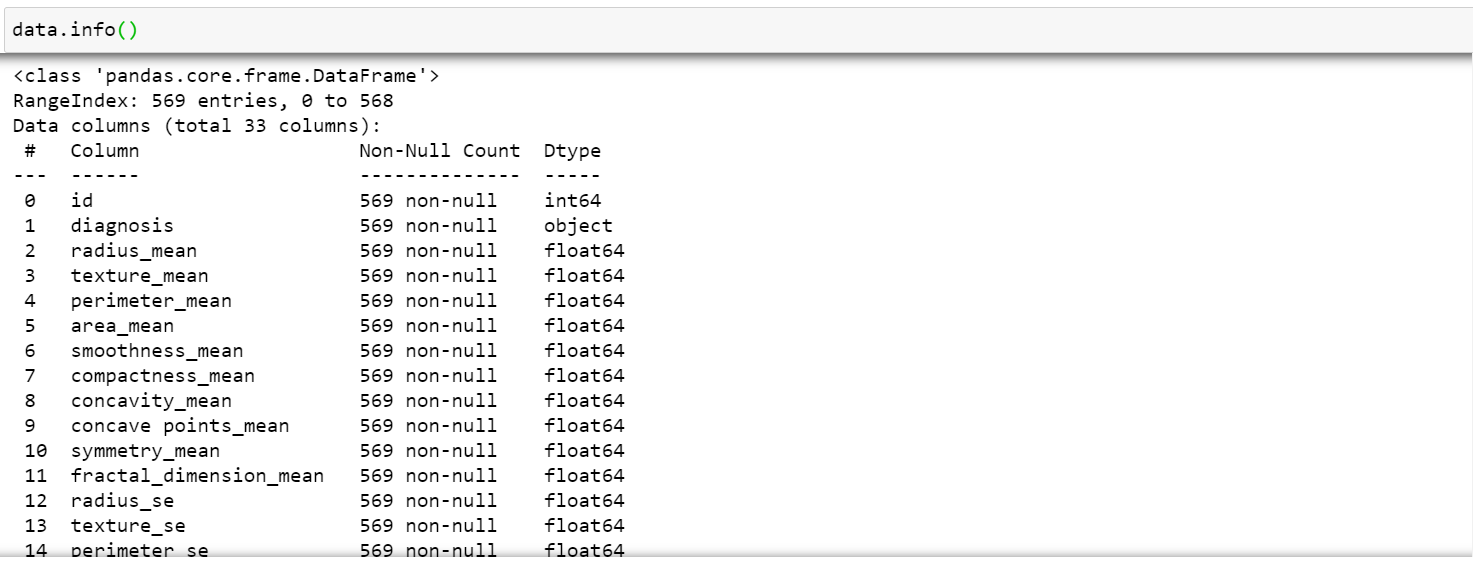
c. summary of the datatypes and missing values: Run,
data.info()
6. Data Cleaning and preprocessing : Data Cleaning involves identifying and removing errors & duplicate observations from the dataset. Most dataset contain missing values or/and invalid columns that you will need to remove to get your data ready for modelling. Visualizing our dataset, you will observe that the diagnosis column which is the target(column that holds the classes you aim to predict) holds values that are non-numeric.We have got to encode it.
a. Run the following to encode data points in that column.
encoder=LabelEncoder() # create an instance of the encoder
data['diagnosis']=encoder.fit_transform(data['diagnosis']) # fit data to encoder
b. Run the following to split data into features and target.
y = data['diagnosis']
X = data.drop(['diagnosis','Unnamed: 32'],1)# drop target column and invalid column in the dataset.
7. Split data into train and test set: Run code below to split the data. We split the data into 2 sets - train set(80 percent of the data) and test set(20 percent of the data)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size = 0.2,random_state=42)
8. Building the Classifier:
a. create an instance of the algorithm:
model=DecisionTreeClassifier()
b. fit data into algorithm
model.fit(X_train,y_train)
9. Evaluating the model: Recall that we split the data to 2 set. a. Use model to predict the test set
y_pred=model.predict(X_test)
b. use evaluation metric to score the model performance
accuracy_score(y_test,y_pred)
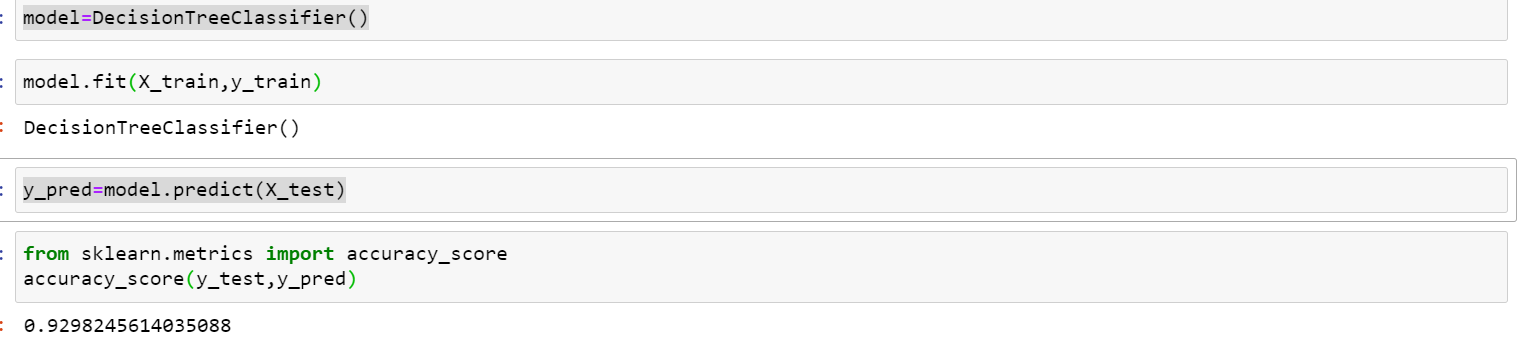
Our model did pretty well😊, about ninety three percent accurate. Kudos!!!!🙌
Conclusion
The study covers a skeletal framework of building a machine learning classifier. I really hope , it was a smooth ride. It's time to pick up an amazing classification project. Thanks for reading🎉❤